Re: [tip:core/locking] x86/smp: Move waiting on contended ticketlock out of line
From: Davidlohr Bueso
Date: Wed Feb 27 2013 - 23:06:49 EST
On Wed, 2013-02-27 at 21:58 -0500, Rik van Riel wrote:
> On 02/27/2013 05:13 PM, Linus Torvalds wrote:
> >
> > On Feb 27, 2013 1:56 PM, "Rik van Riel" <riel@xxxxxxxxxx
> > <mailto:riel@xxxxxxxxxx>> wrote:
> >>
> >> No argument there, but that does in no way negate the need for some
> >> performance robustness.
> >
> > The very numbers you posted showed that the backoff was *not* more
> > robust. Quite the reverse, there was arguably more variability.
>
> On the other hand, both MCS and the fast queue locks
> implemented by Michel showed low variability and high
> performance.
>
> http://thread.gmane.org/gmane.linux.kernel/1427417
>
> > So I really don't like how you make these sweeping statements
> > *again*. Numbers talk, bullshit walks.
>
> If you read all the text in my last mail, you will see the
> link to Michel's performance results. The numbers speak for
> themselves.
>
> > The fact is, life is complicated. The simple spinlocks tend to work
> > really well. People have tried fancy things before, and it turns out
> > it's not as simple as they think.
>
> The numbers for both the simple spinlocks and the
> spinlock backoff kind of suck. Both of these have
> high variability, and both eventually fall down
> under heavy load.
>
> The numbers for Michel's MCS and fast queue lock
> implementations appear to be both fast and stable.
>
> I agree that we need numbers.
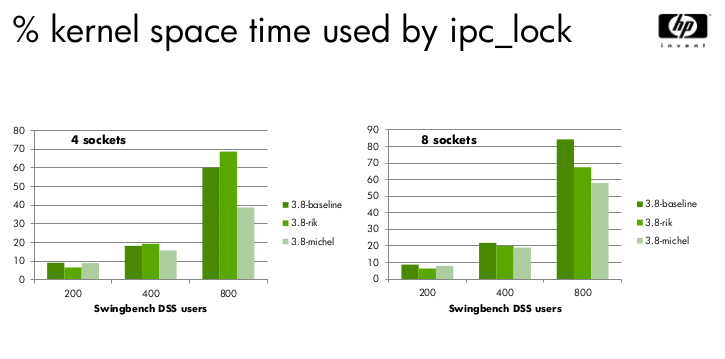
FWIW I've been doing some benchmarking for Swingbench DSS workloads
(Oracle data mining) comparing Rik and Michel's patches. With lower
amounts of contention, Rik's ticket spinlock is better, but once
contention gets high enough the queued locks performs better.
The attached file shows how the amount of sys time used by the ipc lock
for a 4 and 8 socket box.
Attachment:
dss-ipclock.png
Description: PNG image
{kind=link}