[PATCH v6 0/2]: perf: reduce data loss when profiling highly parallel CPU bound workloads
From: Alexey Budankov
Date: Tue Sep 04 2018 - 07:54:40 EST
Currently in record mode the tool implements trace writing serially.
The algorithm loops over mapped per-cpu data buffers and stores
ready data chunks into a trace file using write() system call.
At some circumstances the kernel may lack free space in a buffer
because the other buffer's half is not yet written to disk due to
some other buffer's data writing by the tool at the moment.
Thus serial trace writing implementation may cause the kernel
to loose profiling data and that is what observed when profiling
highly parallel CPU bound workloads on machines with big number
of cores.
Experiment with profiling matrix multiplication code executing 128
threads on Intel Xeon Phi (KNM) with 272 cores, like below,
demonstrates data loss metrics value of 98%:
/usr/bin/time perf record -o /tmp/perf-ser.data -a -N -B -T -R -g \
--call-graph dwarf,1024 --user-regs=IP,SP,BP \
--switch-events -e cycles,instructions,ref-cycles,software/period=1,name=cs,config=0x3/Duk -- \
matrix.gcc
Data loss metrics is the ratio lost_time/elapsed_time where
lost_time is the sum of time intervals containing PERF_RECORD_LOST
records and elapsed_time is the elapsed application run time
under profiling.
Applying asynchronous trace streaming thru Posix AIO API
(http://man7.org/linux/man-pages/man7/aio.7.html)
lowers data loss metrics value providing 2x improvement -
lowering 98% loss to almost 0%.
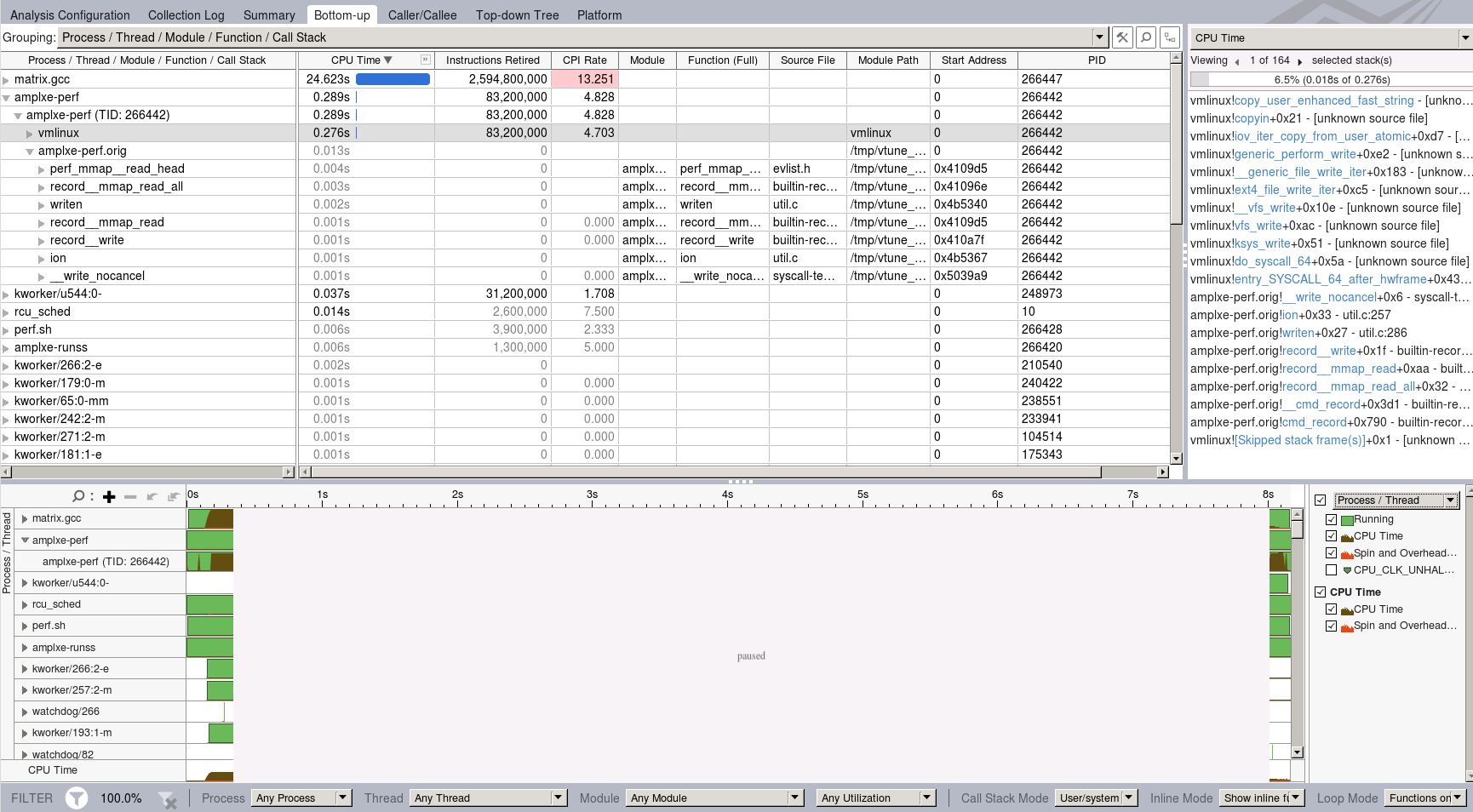
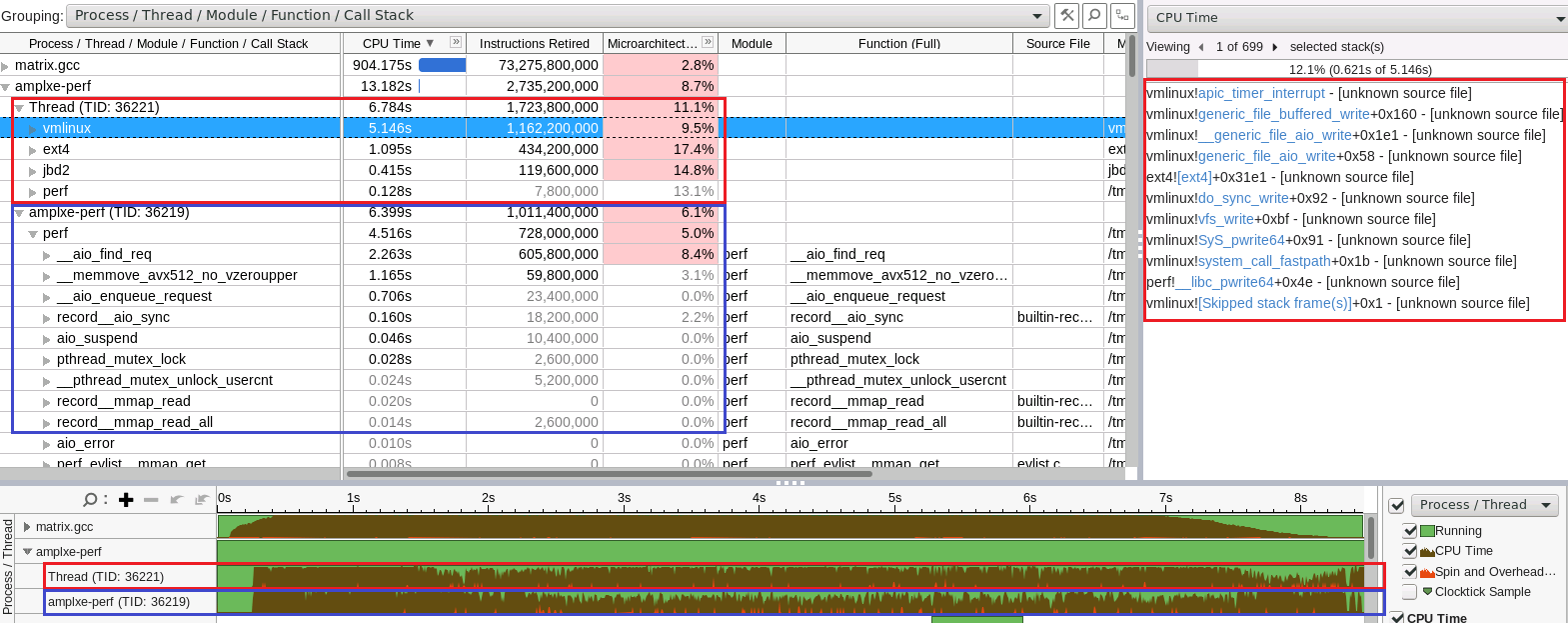
Attached screenshots demonstrate the advantage of applying
AIO streaming for perf record mode. lost_time is the sum of paused
gray intervals (sec) at the bottom of the picture in the timeline
view. elapsed_time is the duration (sec) of the collection on
the timeline in the bottom.
The data loss metrics is decreased when moving from serial
(trace_serial.1024.png) to AIO streaming (trace_aio.v5.sav2.nr8.stack1024.png)
because Perf tool manages to collect more data and clarify
more parts of the long paused region from the serial case.
---
Alexey Budankov (2):
perf util: map data buffer for preserving collected data
perf record: enable asynchronous trace writing
tools/perf/builtin-record.c | 194 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++---
tools/perf/perf.h | 1 +
tools/perf/util/evlist.c | 7 +++---
tools/perf/util/evlist.h | 3 ++-
tools/perf/util/mmap.c | 110 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++------------
tools/perf/util/mmap.h | 10 +++++---
6 files changed, 299 insertions(+), 26 deletions(-)
---
Changes in v6:
- adjusted setting of priorities for cblocks;
- handled errno == EAGAIN case from aio_write() return;
Changes in v5:
- resolved livelock on perf record -e intel_pt// -- dd if=/dev/zero of=/dev/null count=100000
- data loss metrics decreased from 25% to 2x in trialed configuration;
- reshaped layout of data structures;
- implemented --aio option;
- avoided nanosleep() prior calling aio_suspend();
- switched to per-cpu aio multi buffer record__aio_sync();
- record_mmap_read_sync() now does global sync just before
switching trace file or collection stop;
Changes in v4:
- converted mmap()/munmap() to malloc()/free() for mmap->data buffer management
- converted void *bf to struct perf_mmap *md in signatures
- written comment in perf_mmap__push() just before perf_mmap__get();
- written comment in record__mmap_read_sync() on possible restarting
of aio_write() operation and releasing perf_mmap object after all;
- added perf_mmap__put() for the cases of failed aio_write();
Changes in v3:
- written comments about nanosleep(0.5ms) call prior aio_suspend()
to cope with intrusiveness of its implementation in glibc;
- written comments about rationale behind coping profiling data
into mmap->data buffer;
Changes in v2:
- converted zalloc() to calloc() for allocation of mmap_aio array,
- cleared typo and adjusted fallback branch code;
---
tools/perf/perf test
1: vmlinux symtab matches kallsyms : Skip
2: Detect openat syscall event : Ok
3: Detect openat syscall event on all cpus : Ok
4: Read samples using the mmap interface : Ok
5: Test data source output : Ok
6: Parse event definition strings : Ok
7: Simple expression parser : Ok
8: PERF_RECORD_* events & perf_sample fields : Ok
9: Parse perf pmu format : Ok
10: DSO data read : Ok
11: DSO data cache : Ok
12: DSO data reopen : Ok
13: Roundtrip evsel->name : Ok
14: Parse sched tracepoints fields : Ok
15: syscalls:sys_enter_openat event fields : Ok
16: Setup struct perf_event_attr : Skip
17: Match and link multiple hists : Ok
18: 'import perf' in python : FAILED!
19: Breakpoint overflow signal handler : Ok
20: Breakpoint overflow sampling : Ok
21: Breakpoint accounting : Ok
22: Number of exit events of a simple workload : Ok
23: Software clock events period values : Ok
24: Object code reading : Ok
25: Sample parsing : Ok
26: Use a dummy software event to keep tracking : Ok
27: Parse with no sample_id_all bit set : Ok
28: Filter hist entries : Ok
29: Lookup mmap thread : Ok
30: Share thread mg : Ok
31: Sort output of hist entries : Ok
32: Cumulate child hist entries : Ok
33: Track with sched_switch : Ok
34: Filter fds with revents mask in a fdarray : Ok
35: Add fd to a fdarray, making it autogrow : Ok
36: kmod_path__parse : Ok
37: Thread map : Ok
38: LLVM search and compile :
38.1: Basic BPF llvm compile : Skip
38.2: kbuild searching : Skip
38.3: Compile source for BPF prologue generation : Skip
38.4: Compile source for BPF relocation : Skip
39: Session topology : Ok
40: BPF filter :
40.1: Basic BPF filtering : Skip
40.2: BPF pinning : Skip
40.3: BPF prologue generation : Skip
40.4: BPF relocation checker : Skip
41: Synthesize thread map : Ok
42: Remove thread map : Ok
43: Synthesize cpu map : Ok
44: Synthesize stat config : Ok
45: Synthesize stat : Ok
46: Synthesize stat round : Ok
47: Synthesize attr update : Ok
48: Event times : Ok
49: Read backward ring buffer : Ok
50: Print cpu map : Ok
51: Probe SDT events : Ok
52: is_printable_array : Ok
53: Print bitmap : Ok
54: perf hooks : Ok
55: builtin clang support : Skip (not compiled in)
56: unit_number__scnprintf : Ok
57: mem2node : Ok
58: x86 rdpmc : Ok
59: Convert perf time to TSC : Ok
60: DWARF unwind : Ok
61: x86 instruction decoder - new instructions : Ok
62: Use vfs_getname probe to get syscall args filenames : Skip
63: Add vfs_getname probe to get syscall args filenames : Skip
64: Check open filename arg using perf trace + vfs_getname: Skip
65: probe libc's inet_pton & backtrace it with ping : FAILED!
Attachment:
trace_serial.1024.png
Description: PNG image
Attachment:
trace_aio.v5.sav2.nr8.stack1024.png
Description: PNG image
{kind=link}
{kind=link}