Re: Higher than expected disk write(2) latency
From: Martin Sustrik
Date: Thu Jul 10 2008 - 04:12:39 EST
Hi Andrew,
we're getting some rather high figures for write(2) latency when testing
synchronous writing to disk. The test I'm running writes 2000 blocks of
contiguous data to a raw device, using O_DIRECT and various block sizes
down to a minimum of 512 bytes.
The disk is a Seagate ST380817AS SATA connected to an Intel ICH7
using ata_piix. Write caching has been explicitly disabled on the
drive, and there is no other activity that should affect the test
results (all system filesystems are on a separate drive). The system is
running Debian etch, with a 2.6.24 kernel.
Observed results:
size=1024, N=2000, took=4.450788 s, thput=3 mb/s seekc=1
write: avg=8.388851 max=24.998846 min=8.335624 ms
8 ms: 1992 cases
9 ms: 2 cases
10 ms: 1 cases
14 ms: 1 cases
16 ms: 3 cases
24 ms: 1 cases
stoopid question 1: are you writing to a regular file, or to /dev/sda? If
the former then metadata fetches will introduce glitches.
Not a file, just a raw device.
stoopid question 2: does the same effect happen with reads?
Dunno. The read is not critical for us. However, I would expect the same
behaviour (see below).
We've got a satisfying explansation of the behaviour from Roger Heflin:
"You write sector n and n+1, it takes some amount of time for that first
set of sectors to come under the head, when it does you write it and
immediately return. Immediately after that you attempt write sector
n+2 and n+3 which just a bit ago passed under the head, so you have to
wait an *ENTIRE* revolution for those sectors to again come under the
head to be written, another ~8.3ms, and you continue to repeat this with
each block being written. If the sector was randomly placed in the
rotation (ie 50% chance of the disk being off by 1/2 a rotation or
less-you would have a 4.15 ms average seek time for your test)-but the
case of sequential sync writes this leaves the sector about as far as
possible from the head (it just passed under the head)."
Now, the obvious solution was to use AIO to be able to enqueue write
requests even before the head reaches the end of the sector - thus there
would be no need for superfluous disk revolvings.
We've actually measured this scenario with kernel AIO (libaio1) and this
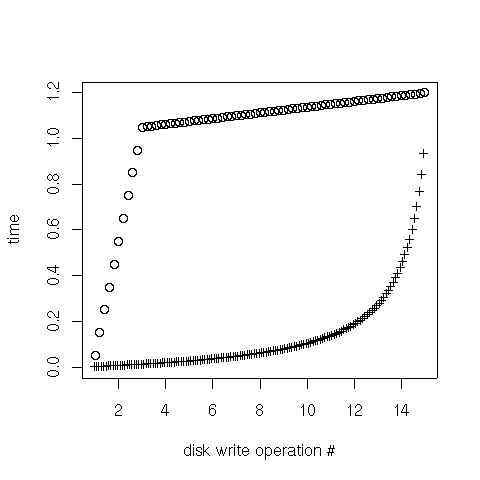
is what we'vew got (see attached graph).
The x axis represents individual write operations, y axis represents
time. Crosses are operations enqueue times (when write requests were
issues), circles are times of notifications (when the app was notified
that the write request was processed).
What we see is that AIO performs rather bad while we are still
enqueueing more writes (it misses right position on the disk and has to
do superfluous disk revolvings), however, once we stop enqueueing new
write request, those already in the queue are processed swiftly.
My guess (I am not a kernel hacker) would be that sync operations on the
AIO queue are slowing down the retrieval from the queue and thus we miss
the right place on the disk almost all the time. Once app stops
enqueueing new write requests there's no contention on the queue and we
are able to catch up with the speed of disk rotation.
If this is the case, the solution would be straightforward: When
dequeueing from AIO queue, dequeue *all* the requests in the queue and
place them into another non-synchronised queue. Getting an element from
a non-sync queue is matter of few nanoseconds, thus we should be able to
process it before head missis the right point on the disk. Once the
non-sync queue is empty, we get *all* the requests from the AIO queue
again. Etc.
Anyone any opinion on this matter?
Thanks.
Martin